Crafting And Executing Strategy Pdf Download
Asciidoctor PDF is a native PDF converter for AsciiDoc. It bypasses the requirement to generate an intermediary format such as DocBook, Apache FO, or LaTeX. Instead, you can use this extension to convert your documents directly from AsciiDoc to PDF. Its aim is to take the pain out of creating PDF documents from AsciiDoc.
| You're viewing the documentation for the 1.6.x release line. If you're looking for the documentation for another release line, please refer to one of the following branches: 2.0.x ⁃ 1.5.x |
Overview
Asciidoctor PDF is an Asciidoctor extension that converts an AsciiDoc document directly to a PDF document. The style and layout of the PDF is controlled by a dedicated theme file. To the degree possible, this converter supports all the features of AsciiDoc that are supported by the built-in converters. However, there are certain limits imposed by the PDF format and the PDF library this extension uses.
Under the covers, Asciidoctor PDF uses the Prawn gem and its extensions (e.g., prawn-svg and prawn-table) to generate the PDF document. Prawn is a general purpose PDF generator for Ruby that features high-level APIs for common needs like setting up the page and inserting images and low-level APIs for positioning and rendering text and graphics.
Prawn takes the pain out of creating (basic) PDF documents. Likewise, Asciidoctor PDF takes the pain out of creating PDF documents directly from AsciiDoc. Skip ahead to Getting started to start putting Asciidoctor PDF use. But don't miss the Highlights to get a preview of what's possible.
Highlights
-
Direct AsciiDoc to PDF conversion
-
Configuration-driven theme (style and layout)
-
Custom fonts (TTF or OTF)
-
Full SVG support (thanks to prawn-svg)
-
PDF document outline (i.e., bookmarks)
-
Title page
-
Table of contents page(s)
-
Document metadata (title, authors, subject, keywords, etc.)
-
Configurable page size (e.g., A4, Letter, Legal, etc)
-
Internal cross reference links
-
Syntax highlighting with Rouge (preferred), Pygments, or CodeRay
-
Cover pages
-
Page background color or page background image with named scaling
-
Page numbering
-
Double-sided (aka prepress) printing mode (i.e., margins alternate on recto and verso pages)
-
Customizable running content (header and footer)
-
"Keep together" blocks (i.e., page breaks avoided in certain block content)
-
Orphaned section titles avoided
-
Autofit verbatim blocks (as permitted by base_font_size_min setting)
-
Table border settings honored
-
Font-based icons
-
Auto-generated index
-
Automatic hyphenation (when enabled)
-
Permissive line breaking for CJK languages
-
Compression / optimization of output file
Known Limitations
-
Footnotes are always rendered as endnotes (at end of chapter for books; at end of document for all other doctypes)
-
Table cells that exceed the height of a single page will be truncated (see prawn-table#41)
-
Inline images in table cells must fit within available space or Prawn::Errors::CannotFit error will be thrown
-
Columns cannot be assigned a 0% width (or a width less than the width of a single character); in the same vein, a column cannot be set to autowidth if width of all other columns meets or exceeds 100%; the result is that the converter with throw a Prawn::Errors::CannotFit error
-
An inline image in a table cell will not force the column wider if the width of the image exceeds the width of the column; either reduce the image width using
pdfwidthor increase the width of the column usingcols; another solution is to convert the cell to an AsciiDoc table cell (see https://github.com/asciidoctor/asciidoctor-pdf/issues/830) -
Must use development version of prawn-table for autowidth to work on table head row
-
Must use development version of prawn for error to include font name when requested font style is missing
-
Must use Ruby >= 2.4 for natural cross references to work with non-ASCII titles
-
AsciiDoc table cell leaves padding below last block (due to lack of margin collapsing)
-
Prawn does not support double-wide box drawing glyphs correctly, so box drawings aren't aligned properly in verbatim blocks (see prawn#1002
-
Orphan / widow support is limited; a page break can occur between a section title and its section content, a table caption and the caption, etc.; use a manual page break to avoid
-
If a no-break hyphen is surrounded by formatted text on both sides (or is formatted individually), it will not prevent a line break
-
Images cannot float
Prerequisites
All that's needed is Ruby (Ruby 2.5 or better) and a few Ruby gems (including at least Asciidoctor 2.0.0), which we explain how to install in the next section.
To check if you have Ruby available, use the ruby command to query the version installed:
Make sure this command reports a Ruby version that's at least 2.5. If so, you may proceed.
If you want to optimize the pdf using rghost or hexapdf, you'll need to install the rghost gem:
or the hexapdf gem:
Similarly, if you want to use the hyphen option you will need to install the text-hyphen gem:
$ gem install text-hyphen
You'll also need to install a syntax highlighter to use source highlighting.
System Encoding
Asciidoctor assumes you're using UTF-8 encoding. To minimize encoding problems, make sure the default encoding of your system is set to UTF-8.
If you're using a non-English Windows environment, the default encoding of your system may not be UTF-8. As a result, you may get an Encoding::UndefinedConversionError or other encoding issues when invoking Asciidoctor. To solve these problems, we recommend at least changing the active code page in your console to UTF-8.
Once you make this change, all your Unicode headaches will be behind you.
Getting Started
You can get Asciidoctor PDF by installing the published gem.
Install the Published Gem
To install Asciidoctor PDF, first make sure you have satisfied the prerequisites. Then, install the gem from RubyGems.org using the following command:
$ gem install asciidoctor-pdf
Installation Troubleshooting
If you get a permission error while installing the gem, such as the one below, it's likely you're attempting to install the gem directly into your system. Installing gems for tech writing directly into your system is not recommended.
Permission error when attempting to install as a system gem
ERROR: While executing gem ... (Gem::FilePermissionError) You don't have write permissions for the /Library/Ruby/Gems/2.x.x directory.
A better practice (and one that will ensure your sanity) is to ignore any version of Ruby installed on your system and use RVM to manage the Ruby installation instead. The benefit of this approach is that a) Ruby is guaranteed to be set up correctly, b) installing gems will in no way interfere with the operation of your system, and c) any bin scripts provided by the installed gems will be available on your PATH. All files are managed in user space (aka your home or user directory). If something gets messed up, you can simply remove the $HOME/.rvm folder and start over.
To learn how to install RVM, follow the RVM installation procedure covered in the Asciidoctor documentation. Once you have installed RVM and used it to install Ruby, make sure to activate the Ruby managed by RVM using rvm use default or a specific Ruby version like rvm use 2.7. (You'll need to do this each time you open a new terminal).
After installing the gem, you can see where it was installed using the following command:
$ gem which asciidoctor-pdf
To see where the bin script is located, use this command:
$ command -v asciidoctor-pdf
Both paths should be underneath the $HOME/.rvm directory. If not, check your RVM setup.
Install a Syntax Highlighter (optional)
If you want to syntax highlight source listings, you'll also want to install Rouge, Pygments, or CodeRay. Choose one (or more) of the following:
Rouge (preferred, minimum version: 2.0.0)
Pygments
$ gem install pygments.rb
You then activate syntax highlighting for a given document by adding the source-highlighter attribute to the document header (Rouge shown):
:source-highlighter: rouge Upgrade Prawn and Extensions (optional)
Asciidoctor PDF uses Prawn to handle the PDF generation, which has a different release cycle. At times, there may be development features in Prawn and its extensions you need to use which haven't yet been released. No problem. You can still gain access to these features by installing the unreleased gems directly from GitHub.
To get started, first create a Gemfile in the root of your project. In that file, declare the gem source, the asciidoctor-pdf gem, and the prawn gem and/or one of its extension gems. In this example, we'll install both the prawn and prawn-table gems from GitHub.
Gemfile
source ' https://rubygems.org ' gem ' asciidoctor-pdf ' gem ' prawn ' , github: ' prawnpdf/prawn ' gem ' prawn-table ' , github: ' prawnpdf/prawn-table ' You can then install the gems into your project using the bundle command:
$ bundle config set --local path .bundle/gems && bundle
Since you're using Bundler to manage the gems, you'll need to prefix all commands with bundle exec. For example:
$ bundle exec asciidoctor-pdf -v
Thus, to any command present in the following sections, be sure to include this prefix.
Run the Application
Assuming all the required gems install properly, verify you can run the asciidoctor-pdf script:
If you see the version of Asciidoctor PDF printed, you're ready to use Asciidoctor PDF!
Let's grab an AsciiDoc document to distill and start putting Asciidoctor PDF to use.
An Example AsciiDoc Document
If you don't already have an AsciiDoc document, you can use the basic-example.adoc file found in the examples directory of this project.
basic-example.adoc
= Document Title Doc Writer <doc@example.com> :reproducible: :listing-caption: Listing :source-highlighter: rouge :toc: // Uncomment next line to add a title page (or set doctype to book) //:title-page: // Uncomment next line to set page size (default is A4) //:pdf-page-size: Letter An example of a basic http://asciidoc.org[AsciiDoc] document prepared by {author}. == Introduction A paragraph followed by an unordered list{empty}footnote:[AsciiDoc supports unordered, ordered, and description lists.] with square bullets.footnote:[You may choose from square, disc, and circle for the bullet style.] [square] * item 1 * item 2 * item 3 == Main Here's how you say "`Hello, World!`" in Prawn: .Create a basic PDF document using Prawn [source,ruby] ---- require 'prawn' Prawn::Document.generate 'example.pdf' do text 'Hello, World!' end ---- == Conclusion That's all, folks! It's time to convert the AsciiDoc document directly to PDF.
Convert AsciiDoc to PDF
You'll need the rouge gem installed to run this example since it uses the source-highlighter attribute with the value of rouge. |
Converting to PDF is as simple as running the asciidoctor-pdf script using Ruby and passing our AsciiDoc document as the first argument.
$ asciidoctor-pdf basic-example.adoc
This command is just a shorthand way of running:
$ asciidoctor -r asciidoctor-pdf -b pdf basic-example.adoc
The asciidoctor-pdf command just saves you from having to remember all those flags. That's why we created it.
When the script completes, you should see the file basic-example.pdf in the same directory. Open the basic-example.pdf file with a PDF viewer to see the result.
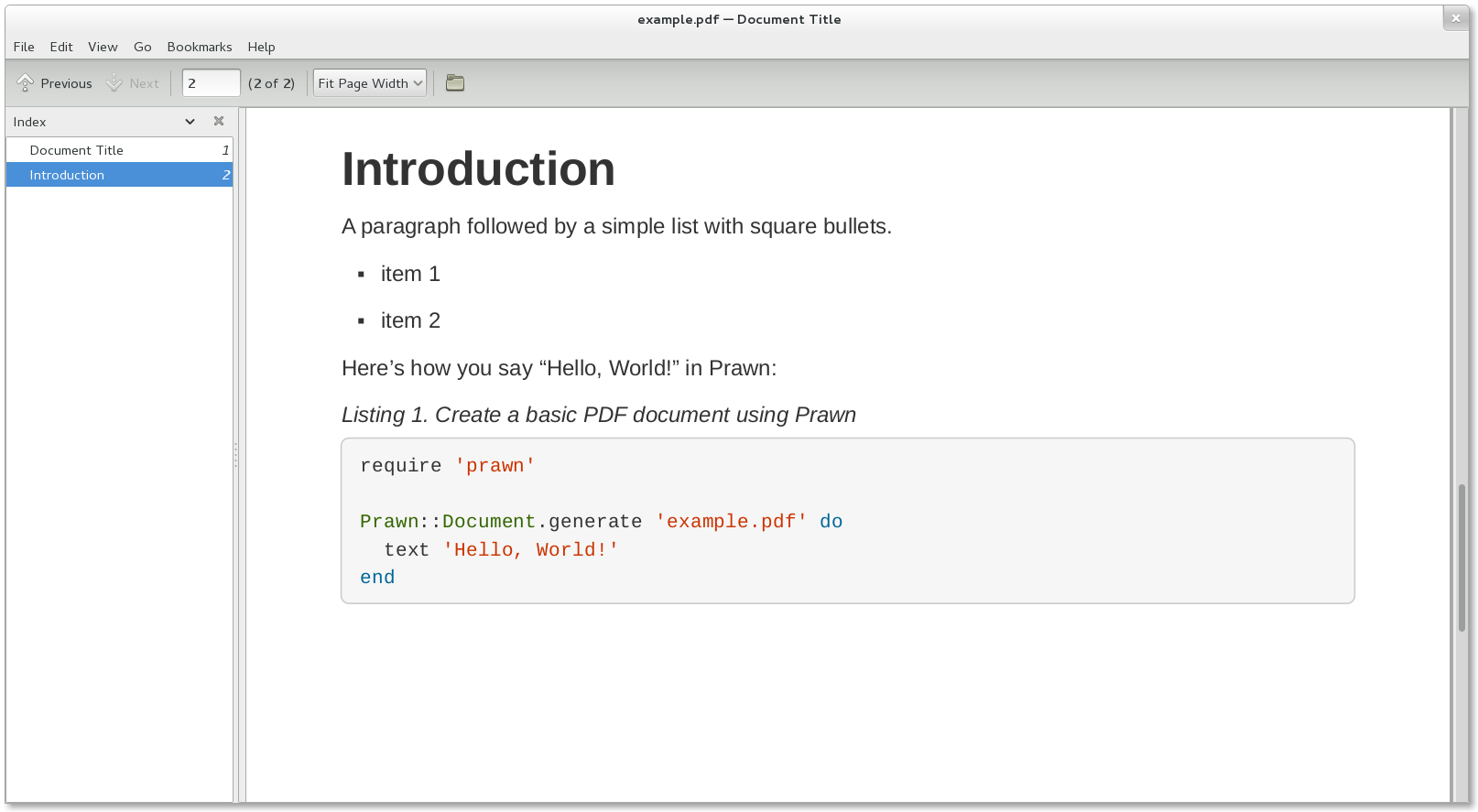
Figure 1. Example PDF document rendered in a PDF viewer
The pain of the DocBook toolchain should be melting away about now.
Themes
The layout and styling of the PDF is driven by a YAML configuration file. To learn how the theming system works and how to create and apply custom themes, refer to the Asciidoctor PDF Theming Guide. You can use the built-in theme files, which you can find in the data/themes directory, as examples.
If you've enabled a source highlighter, you can control the style (aka theme) it applies to source blocks using the coderay-style, pygments-style, and rouge-style attributes, respectively. For example, to configure Rouge to use the built-in monokai theme, run Asciidoctor PDF as follows:
$ asciidoctor-pdf -a rouge-style=monokai basic-example.adoc
Support for Non-Latin Languages
Asciidoctor can process the full range of characters in the UTF-8 character set. That means you can write your document in any language, save the file with UTF-8 encoding (that's important!), and expect Asciidoctor to convert the text properly. But you still need a font that provides the glyphs for those characters.
When converting a document with Asciidoctor PDF, you may notice that some glyphs for certain languages, such as Chinese, are missing from the PDF. PDF is a "bring your own font" kind of system. In other words, the font you provide must provide glyphs for all the characters used. There's no one font that supports all the world's languages (though some, like Noto Serif, certainly come close). Even if there were such a font, bundling that font with the main gem would make it enormous. It would also severely limit the style choices in the default theme, which targets Latin-based languages. Therefore, we're taking the strategy of creating separate dedicated theme gems that target each language family, such as CJK. Read on to find out how to use these themes.
Asciidoctor PDF provides a built-in theme that provides a broad range of characters in the CJK charsets, so you can start with that theme:
$ asciidoctor-pdf -a scripts=cjk -a pdf-theme=default-with-fallback-font document.adoc
Notice the -a scripts=cjk option. That's important. It tells the converter to insert break opportunities between CJK characters so that the line wraps properly when mixing English and a CJK language like Japanese.
If the built-in theme with the fallback font doesn't go far enough, you'll need to use a theme that is optimized for CJK text. You can get such a theme by installing the asciidoctor-pdf-cjk-kai_gen_gothic gem. The asciidoctor-pdf-cjk-kai_gen_gothic project provides themes optimized for CJK languages based on the kai_gen_gothic font. See the asciidoctor-pdf-cjk-kai_gen_gothic project README for detailed setup instructions.
Once you have that gem installed (and the fonts), you need to tell Asciidoctor PDF to use one of the themes. If you're converting a document that is primarily written in Japanese, you'd run Asciidoctor PDF as follows:
asciidoctor-pdf -r asciidoctor-pdf-cjk-kai_gen_gothic -a pdf-theme=KaiGenGothicJP document.adoc
You also have to option of creating your own theme gem that uses fonts of your choice. For example, if you want to use the asciidoctor-pdf-cjk-kai_gen_gothic gem to fetch fonts, but then use them in your own theme, here's how you'd do it.
-
Install the
asciidoctor-pdf-cjk-kai_gen_gothicgem:$ gem install asciidoctor-pdf-cjk-kai_gen_gothic
-
Download / install the fonts:
$ asciidoctor-pdf-cjk-kai_gen_gothic-install
-
Create a theme that extends the default theme:
extends: default font: catalog: KaiGen Gothic JP: normal: KaiGenGothicJP-Regular.ttf bold: KaiGenGothicJP-Bold.ttf italic: KaiGenGothicJP-Regular-Italic.ttf bold_italic: KaiGenGothicJP-Bold-Italic.ttf M+ 1mn: normal: GEM_FONTS_DIR/mplus1mn-regular-subset.ttf bold: GEM_FONTS_DIR/mplus1mn-bold-subset.ttf italic: GEM_FONTS_DIR/mplus1mn-italic-subset.ttf bold_italic: GEM_FONTS_DIR/mplus1mn-bold_italic-subset.ttf fallbacks: - KaiGen Gothic JP base: font-family: KaiGen Gothic JP heading: font-family: $base-font-family abstract: title: font-family: $heading-font-family sidebar: title: font-family: $heading-font-family -
Load your theme when running Asciidoctor PDF:
$ asciidoctor-pdf -a scripts=cjk -a pdf-theme=./jp-theme.yml -a pdf-fontsdir=`ruby -r asciidoctor-pdf-cjk-kai_gen_gothic -e "print File.expand_path '../fonts', (Gem.datadir 'asciidoctor-pdf-cjk-kai_gen_gothic')"` document.adoc
The -a pdf-fontsdir option is important to tell Asciidoctor PDF where to find your custom fonts.
Rather than using the installer from the asciidoctor-pdf-cjk-kai_gen_gothic gem, you can download fonts whatever way you choose. When using your own fonts, be sure to consult the Preparing a Custom Font section of the theming guide to find recommended modifications.
Font-Based Icons
You can use icons in your PDF document using any of the following icon sets:
-
fa - https://fontawesome.com/v4.7.0/icons (default)
-
fas - Font Awesome - Solid
-
fab - Font Awesome - Brands
-
far - Font Awesome - Regular
-
fi - Foundation Icons
-
pf - Payment font
The fa icon set is deprecated. Please use one of the other three FontAwesome icon sets.
You can enable font-based icons by setting the following attribute in the header of your document:
If you want to override the font set globally, also set the icon-set attribute:
:icons: font :icon-set: pf Here's an example that shows how to use the Amazon icon from the payment font (pf) icon set in a sentence (assuming the icon-set is set to `pf):
Available now at icon:amazon[]. You can use the set attribute on the icon macro to override the icon set for a given icon.
Available now at icon:amazon[set=pf]. You can also specify the font set using the following shorthand.
Available now at icon:amazon@pf[]. In addition to the sizes supported in the HTML backend (lg, 1x, 2x, etc), you can enter any relative value in the size attribute (e.g., 1.5em, 150%, etc).
You can enable use of fonts during PDF generation (instead of in the document header) by passing the icons attribute to the asciidoctor-pdf command.
$ asciidoctor-pdf -a icons=font -a icon-set=pf sample.adoc
Icon-based fonts are handled by the prawn-icon gem. To find a complete list of available icons, consult the prawn-icon repository.
Image Paths
Images are resolved at the time the converter runs. That means they need to be located where the converter can find them.
Relative images paths in the document are resolved relative to the value of the imagesdir attribute. This is effectively the same as how the built-in HTML converter works when the data-uri attribute is set. The imagesdir is blank by default, which means relative images paths are resolved relative to the input document. Relative images paths in the theme are resolved relative to the value of the pdf-themesdir attribute (which defaults to the directory of the theme file). The imagesdir attribute is not used when resolving an image path in the theme file. Absolute image paths are used as is.
If the image is an SVG, and the SVG includes a nested raster image (PNG or JPG) with a relative path, that path is resolved relative to the directory that contains the SVG.
The converter will refuse to embed an image if the target is a URI (including image references in an SVG) unless the allow-uri-read attribute is enabled via the CLI or API.
If you use a linked image in an SVG, the width and height of that image must be specified. Otherwise, the SVG library will fail to process it.
Asciidoctor Diagram Integration
Asciidoctor PDF provides seamless integration with Asciidoctor Diagram by setting the data-uri attribute by default. When the data-uri attribute is set, Asciidoctor Diagram returns the absolute path to the generated image, which Asciidoctor PDF can then locate. (This makes sense since technically, Asciidoctor Diagram must embed the image in the document, similar in spirit to the data-uri feature for HTML). This means the input directory and the output directory (and thus the imagesoutdir) can differ and Asciidoctor PDF will still be able to locate the generated image.
Image Scaling
Since PDF is a fixed-width canvas, you almost always need to specify a width to get the image to fit properly on the page. There are five ways to specify the width of an image, listed here in order of precedence:
| Attribute Name | Description |
|---|---|
| pdfwidth | The display width of the image as an absolute size (e.g., 2in), percentage of the content area width (e.g., 75%), or percentage of the page width (e.g., 100vw). If a unit of measurement is not specified (or not recognized), pt (points) is assumed. Intended to be used for the PDF converter only. |
| scaledwidth | The display width of the image as an absolute size (e.g., 2in) or percentage of the content area width (e.g., 75%). If a unit of measurement is not specified, % (percentage) is assumed. If a unit of measurement is recognized, pt (points) is assumed. Intended to be used for print output such as PDF. |
| image_width key from theme | Accepts the same values as pdfwidth. Only applies to block images. |
| width | The unitless display width of the image (assumed to be pixels), typically matching the intrinsic width of the image. If the value ends in % (not recommended), it's assumed to be the percentage of the available content area width. If the width exceeds the content area width, the image is scaled down to the content area width. |
| unspecified | If you don't specify one of the aforementioned width settings, the intrinsic width of the image is used (the px value is multiplied by 75% to convert to pt, assuming canvas is 96 dpi) unless the width exceeds the content area width, in which case the image is scaled down to the content area width. |
The image is always sized according to the explicit or intrinsic width, then its height is scaled proportionally. The height of the image is ignored by the PDF converter unless the height of the image exceeds the content height of the page. In this case, the image is scaled down to fit on a single page.
If you want a block image to align to the boundaries of the page (not the content margin), specify the align-to-page option (e.g., opts="align-to-page"). This is most useful when using vw units because you can make the image cover the entire width of the page.
Images in running content and page background images also support the fit attribute (when specified using the image macro). See Background Image Sizing for details.
Using the pdfwidth Attribute
The pdfwidth attribute is the recommended way to set the image size for the PDF output. This attribute is provided for two reasons. First, the fixed-width canvas often calls for a width that is distinct from other output formats, such as HTML. Second, this attribute allows the width to be expressed using a variety of units.
The pdfwidth attribute supports the following units:
-
pt (default)
-
in
-
cm
-
mm
-
px
-
pc
-
vw (percentage of page width)
-
% (percentage of content area width)
In all cases, the width is converted to pt.
Specifying a Default Width
To scale all block images that don't define either a pdfwidth or scaledwidth attribute on the image macro, assign a value to the image-width key in your theme file.
The image-width key accepts the same values as the pdfwidth attribute. Thus, you can think of it as the fallback value for the pdfwidth attribute. If specified, this value takes precedence over the width attribute on the image macro.
Inline Image Sizing
Inline images can be sized in much the same way as block images (using the pdfwidth, scaledwidth or width attributes), with the following exceptions:
-
The viewport width unit (i.e., vw) is not recognized in this context.
-
The image will be scaled down, if necessary, to fit the width and height of the content area.
-
Inline images do not currently support a default width controlled from the theme.
To confine the inline image to the height of the line while preserving the aspect ratio, use the attribute fit=line.
If the resolved height of the image is less than or equal to 1.5 times the line height, the image won't disrupt the line height and is centered vertically in the line. This is done to maximize the use of available space. Once the resolved height exceeds this amount, the height of the line is increased (by increasing the font size of the invisible placeholder text) to accommodate the image. In this case, the surrounding text will be aligned to the bottom of the image. If the image height exceeds the height of the page, the image will be scaled down to fit on a single page (this may cause the image to advance to the subsequent page).
Background Image Sizing
In addition to the width-related attributes previously covered, cover and background images can be sized relative to the page using the fit attribute of the image macro. The fit attribute works similarly to the object-fit property in CSS. Its value must be specified as a single keyword, chosen from the table below. The starting size of the image is determined by the explicit width, if specified, or the implicit width. The height is always derived from the width while respecting the implicit aspect ratio of the image. The available space for a background image (i.e., the canvas) is the page. If the fit attribute is not specified, it defaults to contain (i.e., the image is automatically scaled to fit the bounds of the page).
| Value | Purpose |
|---|---|
| contain | The image is scaled up or down while retaining its aspect ratio to fit within the available space. (default) |
| cover | The image is scaled up or down while retaining its aspect ratio so the image completely covers the available space, even if it means the image must be clipped in one direction. |
| scale-down | The image is scaled down while retaining its aspect ratio to fit within the available space. If the image already fits, it is not scaled. |
| fill | The image is scaled to fit the available space even if it means modifying the aspect ratio of the image. Does not apply to SVG images. |
| none | The image is not scaled. |
The fit attribute is often combined with the position attribute, covered next, to control the placement of the image on the canvas.
Background Image Positioning
In addition to scaling, background images for cover pages, content pages, and the title page support positioning via the position attribute. The position attribute accepts a syntax similar to the background-position property in CSS, except only the keyword positions are supported. The position consists of two values, the vertical position and the horizontal position (e.g., top center). If only one value is specified (e.g., top), the other value is assumed to be center. If the position attribute is not specified, the value is assumed to be center center (i.e., the image is centered on the page).
The following table provides a list of the vertical and horizontal positioning keywords that are supported. You can use any combination of these keywords to position the image.
| Vertical Positions | Horizontal Positions |
|---|---|
| top | left |
Here's an example of how to place a background image at the top center of every page:
:page-background-image: image:bg.png[fit=none,pdfwidth=50%,position=top]
Here's how to move it to the bottom right:
:page-background-image: image:bg.png[fit=none,pdfwidth=50%,position=bottom right]
If an image dimension matches the height or width of the page, the positioning keyword for that axis has no effect.
Fonts in SVG Images
Asciidoctor PDF uses prawn-svg to embed SVGs in the PDF document, including SVGs generated by Asciidoctor Diagram.
Actually, it's not accurate to say that prawn-svg embeds the SVG. Rather, prawn-svg is an SVG renderer. prawn-svg translates an SVG into native PDF text and graphic objects. You can think of the SVG as a sequence of drawing commands. The result becomes indistinguishable from other PDF objects.
What that means for text is that any font family used for text in the SVG must be registered in the Asciidoctor PDF theme file (and thus with Prawn). Otherwise, Prawn will fallback to using the closest matching built-in (afm) font from PDF (e.g., sans-serif becomes Helvetica). Recall that afm fonts only support basic Latin. As we like to say, PDF is bring your own font.
If you're using Asciidoctor Diagram to generate SVGs to embed in the PDF, you likely need to specify the default font the diagramming tool uses. Let's assume you are making a plantuml diagram.
To set the font used in the diagram, first create a file named plantuml.cfg and populate it with the following content:
skinparam defaultFontName Noto Serif
| You can choose any font name that is registered in your Asciidoctor PDF theme file. When using the default theme, your options are "Noto Serif", "M+ 1mn", and "M+ 1p Fallback". |
Next, pass that path to the plantumlconfig attribute in your AsciiDoc document (or set the attribute via the CLI or API):
:plantumlconfig: plantuml.cfg
Clear the cache of your diagrams and run Asciidoctor PDF with Asciidoctor Diagram enabled. The diagrams will be generated using Noto Serif as the default font, and Asciidoctor PDF will know what to do.
The bottom line is this: If you're using fonts in your SVG, and you want those fonts to be preserved, those fonts must be defined in the Asciidoctor PDF theme file.
Supporting Additional Image File Formats
In order to embed an image into a PDF, Asciidoctor PDF must understand how to read it. To perform this work, Asciidoctor delegates to the underlying libraries. Prawn provides support for reading JPG and PNG images. prawn-svg brings support for SVG images. Without any additional libraries, those are the only supported image file formats.
If you need support for additional image formats, such as GIF, TIFF, or interlaced PNG—and you don't want to convert those images to a supported format—you must install the prawn-gmagick (>= 0.0.9) Ruby gem. prawn-gmagick is an extension for Prawn based on GraphicsMagick that adds support for all the image formats recognized by that library. prawn-gmagick has the added benefit of significantly reducing the time it takes to generate a PDF containing a lot of images.
The prawn-gmagick gem uses native extensions to compile against GraphicsMagick. This system prerequisite limits installation to Linux and OSX. Please refer to the README for prawn-gmagick to learn how to install it.
Once this gem is installed, Asciidoctor automatically loads it, then delegates to it to handle all image embedding. In addition to support for additional image file formats, this gem also speeds up image processing considerably. We highly recommend using this gem if you're able to install it.
Importing PDF Pages
In addition to using a PDF page for the front or back cover, you can also insert a PDF page at an arbitrary location. This technique is useful to include pages that have complex layouts and graphics prepared in a specialized design program (such as Inkscape), which would otherwise not be achievable using this converter. One such example is an insert such as an advertisement or visual interlude.
To import the first page from a PDF file, use the block image macro with the PDF filename as the image target.
The converter will insert the page from the PDF as a dedicated page that matches the size and layout of the page being imported (no matter where the block image occurs). Therefore, there's no need to put a manual page break (i.e., <<<) around the image macro.
By default, this macro will import the first page of the PDF. To import a different page, specify it as a 1-based index using the page attribute.
image::custom-pages.pdf[page=2] You can import multiple pages either using multiple image macros or using the pages attribute. The pages attribute accepts individual page numbers or page number ranges (two page numbers separated by ..). The values can be separated either by commas or semi-colons. (The syntax is similar to the syntax uses for the lines attribute of the AsciiDoc include directive).
image::custom-pages.pdf[pages=3;1..2] Pages are imported in the order listed.
| An image macro used to imports PDF pages should never be nested inside a delimited block or table cell. It should be a direct descendant of the document or a section. That's because what it imports are entire pages. If it's used inside a delimited block or table cell, the behavior is unspecified. |
Crafting Interdocument Xrefs
This converter produces a single PDF file, which means content from multiple source documents get colocated into the same output file. That means references between documents must necessarily become internal references. These interdocument cross references (i.e., xrefs) will only successfully make that transition if you structure your document in accordance with the rules.
Those rules are as follows:
-
The path segment of the interdocument xref must match the project-relative path of the included document
-
The reference must include the ID of the target element
For instance, if your primary document contains the following include:
include::chapters/chapter-1.adoc[] Then an interdocument xref to an anchor in that chapter must be expressed as:
<<chapters/chapter-1.adoc#_anchor_name,Destination in Chapter 1>> This rule holds regardless of which document the xref is located in.
To resolve the interdocument xref, the converter first checks if the target matches the docname attribute. It then looks to see if the target matches one of the included files. (In both cases, it ignores the file extension). If Asciidoctor cannot resolve the target of an interdocument xref, it simply makes a link (like the HTML converter).
Let's consider a complete example. Assume you are converting the following book document at the root of the project:
= Book Title :doctype: book include::chapters/chapter-1.adoc[] include::chapters/chapter-2.adoc[] Where the contents of chapter 1 is as follows:
== Chapter 1 We cover a little bit here. The rest you can find in <<chapters/chapter-2.adoc#_chapter_2,Chapter 2>>. And the contents of chapter 2 is as follows:
== Chapter 2 Prepare to be educated. This chapter has it all! To begin, jump to <<chapters/chapter-2/first-steps.adoc#_first_steps,first steps>>. <<< include::chapter-2/first-steps.adoc[] And, finally, the contents of the nested include is as follows:
=== First Steps Let's start small. You'll find when you run this example that all the interdocument xrefs become internal references in the PDF.
The reason both the path and anchor are required (even when linking to the top of a chapter) is so the interdocument xref works independent of the converter. In other words, it encodes the complete information about the reference so the converter can sort out where the target is in all circumstances.
STEM Support
Unlike the built-in HTML converter, Asciidoctor PDF does not provide native support for STEM blocks and inline macros (i.e., asciimath and latexmath). That's because Asciidoctor core doesn't process the STEM content itself. It just passes it through to the converter. In the HTML output, Asciidoctor relies on the JavaScript-based MathJax library to parse and render the equations in the browser when the page is loaded. The HTML converter simply wraps the equations in special markup so MathJax can find them.
In order to insert a rendered equation into the PDF, the toolchain has to parse the equations and convert them to a format the PDF writer (Prawn) can understand. That typically means converting to an image.
The recommended solution is an extension named Asciidoctor Mathematical, which we'll cover in this document.
Another solution, which is still under development, uses Mathoid to convert STEM equations to images. Mathoid is a library that invokes MathJax using a headless browser, so it supports both asciimath and latexmath equations. That prototype can be found in the Asciidoctor extensions lab.
Asciidoctor Mathematical
Asciidoctor Mathematical is an extension for Asciidoctor that provides alternate processing of STEM blocks and inline macros (currently only latexmath). After the document has been parsed, the extension locates all the latexmath blocks and inline macros, converts the equations to images using Mathematical, then replaces them with image nodes. Conversion then proceeds as normal.
Asciidoctor Mathematical is a Ruby gem that uses native extensions. It has a few system prerequisites which limit installation to Linux and OSX. Please refer to the installation section in the Asciidoctor Mathematical README to learn how to install it.
Once Asciidoctor Mathematical is installed, you just need to enable it when invoking Asciidoctor PDF using the -r flag:
$ asciidoctor-pdf -r asciidoctor-mathematical sample.adoc
If you're invoking Asciidoctor via the API, all you need to do is require the gem before invoking Asciidoctor:
require ' asciidoctor-mathematical ' Asciidoctor.convert_file ' sample.adoc ' , safe: :safe To get the best quality equations, and the maximize speed of conversion, we recommend configuring Asciidoctor Mathematical to convert equations to SVG. You control this setting using the mathematical-format AsciiDoc attribute:
$ asciidoctor-pdf -r asciidoctor-mathematical -a mathematical-format=svg sample.adoc
Refer to the README for Asciidoctor Mathematical to learn about additional settings and options.
Skipping Passthrough Content
Asciidoctor PDF does not support arbitrary passthrough content. While the basebackend for the PDF converter is html, it only recognizes a limited subset of inline HTML elements that can be mapped to PDF (e.g., a, strong, em, code, ). Therefore, if your content contains passthrough blocks or inlines, you most likely have to use a conditional preprocessor to skip them (and make other arrangements).
Here's an example of how to skip a passthrough block when converting to PDF:
ifndef::backend-pdf[] <script> //... </script> endif::[] Here's an example of how to only enable a passthrough block when converting to HTML5:
ifdef::backend-html5[] <script> //... </script> endif::[] Shaded Blocks and Performance
Certain blocks are rendered with a shaded background, such as verbatim (listing, literal, and source), sidebar, and example blocks. In order to calculate the dimensions of the shaded region, Asciidoctor PDF has to "dry run" the block to determine how many pages it consumes. While this strategy has a low impact when processing shorter blocks, it can drastically deteriorate performance when processing a block that spans dozens of pages. As a general rule of thumb, you should avoid using shaded blocks which span more than a handful of pages.
Autofitting Text
Verbatim blocks often have long lines that don't fit within the fixed width of the PDF canvas. And unlike on the web, the PDF reader cannot scroll horizontally to reveal the overflow text. Therefore, the long lines are forced to wrap. Wrapped lines can make the verbatim blocks hard to read or even cause confusion.
To help address this problem, Asciidoctor PDF provides the autofit option on all verbatim (i.e., literal, listing and source) blocks to attempt to fit the text within the available width. When the autofit option is enabled, Asciidoctor PDF will decrease the font size (as much as it can) until the longest line fits without wrapping.
The converter will not shrink the font size beyond the value of the base_font_size_min key specified in the PDF theme. If that threshold is reached, lines may still wrap. To allow autofit to handle all cases, set base_font_size_min to 0 in your theme. |
Here's an example of the autofit option enabled on a source block:
[source%autofit,java] ---- @SessionScoped public class WidgetRepository { @GET @Produces("application/json") public List<String> listAll(@QueryParam("start") Integer start, @QueryParam("max") Integer max) { ... } } ---- If you want to enable the autofit option globally, set the autofit-option document attribute in the document header (or somewhere before the relevant blocks):
Autowidth Tables
Asciidoctor PDF does support autowidth tables. However, the behavior differs from HTML when the content forces the table to the page boundary. The behavior, which is handled by the prawn-table library, is explained in this section.
If the natural width of all columns (based on the width of the cell content) is less than the width of the page, it behaves as you'd expect. Each column is assigned the width it needs to prevent the content from wrapping.
However, when the natural width of all columns exceeds the width of the page, the behavior may not be what you expect. What prawn-table does is compute how to arrange the table on an infinite canvas, where each column can have a width no greater than the width of the page. Then, it reduces the width of the table by reducing the width of each column proportionally. As a result, columns which reported the width necessary to render without wrapping now no longer do.
The reason this compression is not performed like in HTML is because prawn-table has no awareness of words. Thus, it doesn't know how to redistribute with width intelligently.
To protected against truncation or insufficient width errors, prawn-table wraps text by character. That's why the last character in the cell can end up getting wrapped. (There's a small amount of tolerance built in to prawn-table to address some edge cases, but it's not sufficient to handle all of them).
For the reason just explained, you should be extremely careful with relying on autowidth tables in Asciidoctor PDF, especially when the natural content of the cells forces the table to page boundary. Let experience be your guide.
Printing Page Ranges
The print dialog doesn't understand the page numbers labels (which appear in the running content). Instead, it only considers physical pages. Therefore, to print a range of pages as they are labeled in the document, you need to add the number of front matter pages (i.e., the non-numbered pages) to the page number range in the print dialog.
For example, if you only want to print the first 5 pages labeled with a page number (e.g., 1-5), and there are 2 pages before the page labeled as page 1, you need to add 2 to both numbers in the range, giving you a physical page range of 3-7. That's the range you need to enter into the print dialog.
Title Page
Unlike other converters, the PDF converter introduces a dedicated title page at the start of the document. The title page contains the doctitle, author, date, and revision info. If a front cover image is specified, the title page comes after the front cover. The title page can be styled using the theme and/or reserved page attributes.
The title page is enabled if either of these conditions are met:
-
The document has the
bookdoctype. -
The
title-pageattribute is set (with an empty value) in the document header.
When the title page is enabled, the table of contents (aka TOC) also gets is own page (or pages, if necessary).
Table of Contents
The table of contents (TOC) is not included by default. The TOC is only included if the toc attribute is set on the document.
The placement of the table of contents is fixed, and thus the value of the toc attribute is effectively ignored in this backend. For documents that have the book doctype, the TOC is inserted using discrete pages between the title page and the first page of content. For all other doctypes (unless the title-page attribute is set), the TOC is inserted in the flow of text in between the document title and the first block of content.
While the table of contents is not included by default, the PDF outline is always included. The toclevels attribute controls the depth of both the TOC and the PDF outline (regardless of whether the TOC is enabled).
If a document that has the book doctype includes a preface, an entry for the preface is only included in the TOC if the preface-title is assigned a value (e.g., preface-title=Preface). This value is used as the heading of the preface and as the text of the entry in the TOC. |
Index Catalog
Asciidoctor PDF supports generating an index catalog that itemizes all index terms defined in the document, allowing the reader to navigate the document by keyword.
To get Asciidoctor PDF to generate an index, add a level-1 section flagged with the index style near the end of your document. The converter will automatically populate the catalog with the list of index terms in the document, organized by first letter.
You can use any text you want for the title of the section. The only restriction is that no index terms may be defined below this section.
| Although the catalog is generated automatically, you have to mark the index terms manually. However, you could use an extension, such as a TreeProcessor, to automatically mark index terms. |
Optimizing the Generated PDF
By default, Asciidoctor PDF does not optimize the PDF it generates or compress its streams. This section covers several approaches you can take to optimize your PDF.
Enable Stream Compression
The simplest way to reduce the size of the PDF file is to enable stream compression (using the FlateDecode method). You can enable this feature by setting the compress attribute on the document:
$ asciidoctor-pdf -a compress document.adoc
For a more thorough optimization, you can use the integrated optimizer or hexapdf. Read on to learn how.
rghost
Asciidoctor PDF also provides a flag (and bin script) that uses GhostScript (via rghost) to optimize and compress the generated PDF (with minimal impact on quality). You must have Ghostscript (command: gs) and the rghost gem installed to use it.
Here's an example usage that converts your document and optimizes it:
$ asciidoctor-pdf -a optimize basic-example.adoc
The command will generate an optimized PDF 1.4 file. In addition to optimizing the PDF file, it also converts it from plain PDF to a PDF/X-1a.
If this command fails because the gs command cannot be found, you'll need to set it using the GS environment variable. On Windows, this step is almost always required since the Ghostscript installer does not install the gs command into a standard location. Here's an example that shows how you can override the gs command path:
$ GS=/path/to/gs asciidoctor-pdf -a optimize basic-example.adoc
You'll need to use the technique for assigning an environment variable that's relevant for your system.
The one limitation of generating a PDF/X-1a file is that it does not allow non-ASCII characters in the document metadata fields (i.e., title, author, subject, etc). To workaround this limitation, you can force Ghostscript to generate a PDF 1.3 file using the pdf-version attribute:
$ asciidoctor-pdf -a optimize -a pdf-version=1.3 basic-example.adoc
| Downgrading the PDF version may break the PDF if it contains an image that uses color blending or transparency. Specifically, the text on the page can become rasterized, which causes links to stop working and prevents text from being selected. If you're in this situation, it might be best to try hexapdf instead. |
If you're looking for a smaller file size, you can try reducing the quality of the output file by passing a quality keyword to the optimize attribute (e.g., --optimize=screen). The optimize attribute accepts the following keywords: default (default, same if value is empty), screen, ebook, printer, and prepress. Refer to the Ghostscript documentation to learn what settings these presets affect.
If you've already generated the PDF, and want to optimize it directly, you can use the bin script:
$ asciidoctor-pdf-optimize basic-example.pdf
The command will overwrite the PDF file with an optimized version. You can also try reducing the quality of the output file using the --quality flag (e.g., --quality screen). The --quality flag accepts the following keywords: default (default), screen, ebook, printer, and prepress.
In both cases, if a file is found with the extension .pdfmark and the same rootname as the input file, it will be used to add metadata to the generated PDF document. This file is necessary when using versions of Ghostscript < 8.54, which did not automatically preserve this metadata. You can instruct the converter to automatically generate a pdfmark file by setting the pdfmark attribute (i.e., -a pdfmark) When using a more recent version of Ghostscript, you do not need to generate a .pdfmark file for this purpose.
The asciidoctor-pdf-optimize is not guaranteed to reduce the size of the PDF file. It may actually make the PDF larger. You should probably only consider using it if the file size of the original PDF is several megabytes. |
If you have difficulty getting the rghost gem installed, or you aren't getting the results you expect, you can try the optimizer provided by hexapdf instead.
hexapdf
Another option to optimize the PDF is hexapdf (gem: hexapdf, command: hexapdf). Before introducing it, though, it's important to point out that its license is AGPL. If that's okay with you, read on to learn how to use it.
First, install the hexapdf gem using the following command:
You can then use it to optimize your PDF as follows:
$ hexapdf optimize --compress-pages --force basic-example.pdf basic-example.pdf
This command does not manipulate the images in any way. It merely compresses the objects in the PDF and prunes any unreachable references. But given how much waste Prawn leaves behind, this turns out to reduce the file size substantially.
You can hook this command directly into the converter by providing your own implementation of the Optimizer class. Start by creating a Ruby file named optimizer-hexapdf.rb, then populate it with the following code:
optimizer-hexapdf.rb
require ' hexapdf/cli ' class Asciidoctor::PDF::Optimizer def initialize(*) app = HexaPDF::CLI::Application.new app.instance_variable_set :@force, true @optimize = app.main_command.commands[ ' optimize ' ] end def optimize_file path options = @optimize.instance_variable_get :@out_options options.compress_pages = true #options.object_streams = :preserve #options.xref_streams = :preserve #options.streams = :preserve # or :uncompress @optimize.execute path, path nil rescue # retry without page compression, which can sometimes fail options.compress_pages = false @optimize.execute path, path nil end end To activate your custom optimizer, load this file when invoking the asciidoctor-pdf using the -r flag and set the optimize attribute as well using the -a flag.
$ asciidoctor-pdf -r ./optimizer-hexapdf.rb -a optimize basic-example.adoc
Now you can convert and optimize all in one go.
To see more options that hexapdf optimize offers, run:
For example, to make the source of the PDF a bit more readable (though less optimized), set the stream-related options to preserve (e.g.,, --streams preserve from the CLI or options.streams = :preserve from the API). You can also disable page compressioin (e.g., --no-compress-pages from the CLI or options.compress_pages = false from the API).
hexapdf also allows you to add password protection to your PDF, if that's something you're interested in doing.
Posted by: marnimarnihenningsene0269007.blogspot.com
Source: https://asciidoctor.org/docs/asciidoctor-pdf/

Post a Comment for "Crafting And Executing Strategy Pdf Download"